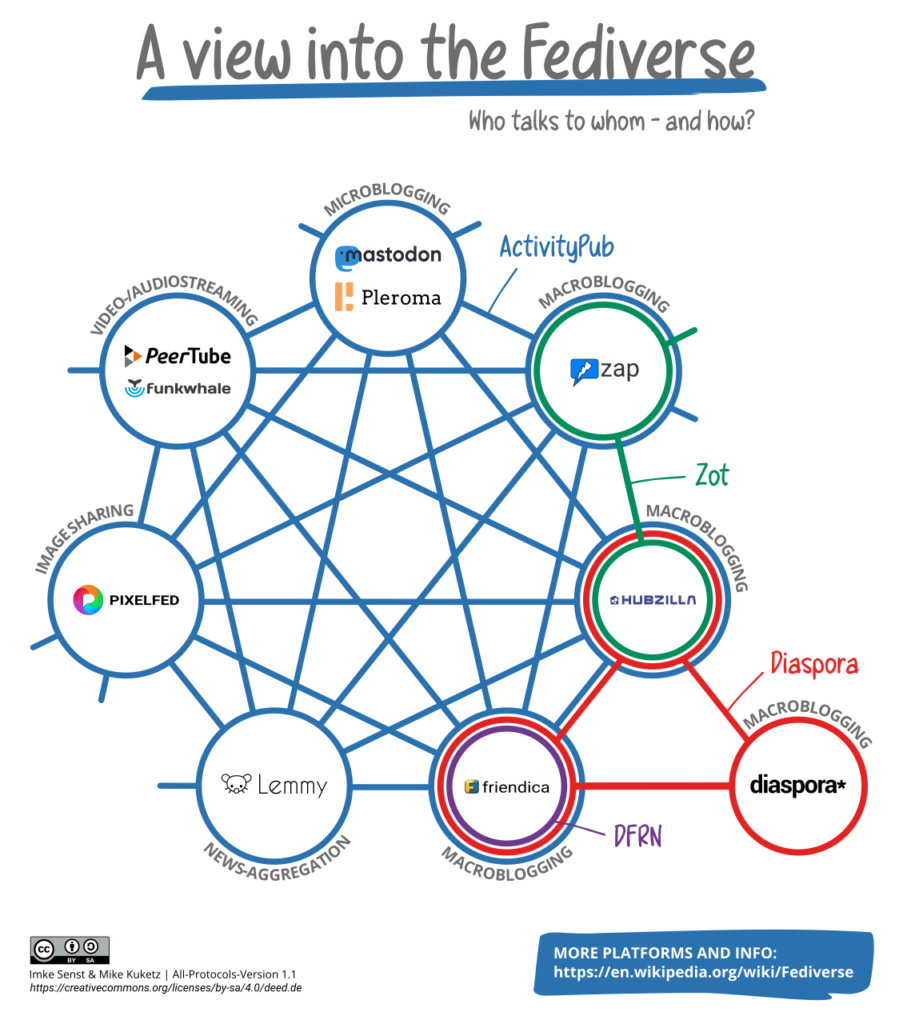
Lorsque j’ai soutenu ma thèse en novembre 2015, je cherchais à définir un modèle pour tous les logiciels malveillants du moment, connectés d’une façon ou d’une autre à leur propriétaire et je défendais en particulier le concept suivant : considérer les botnets non pas comme de simples réseaux de machines compromises, mais comme des ensembles socio-techniques, faits d’acteurs, d’infrastructures, de flux économiques et de contraintes organisationnelles. Cette lecture, qui associe l’analyse technique à une compréhension des dynamiques humaines, conduisait à parler de systèmes plutôt que d’outils isolés, et d’écosystèmes criminels plutôt que de menaces ponctuelles. J’avais également insisté sur la nécessité d’une posture proactive, visant à perturber l’organisation criminelle dans son ensemble — et non seulement ses manifestations visibles.
Dix ans plus tard, cette perspective n’a rien perdu de sa pertinence (Eric Freyssinet, Revue des Mines, 2025). Ce qui a changé, en revanche, c’est l’ampleur du phénomène. Les logiques écosystémiques que l’on observait dans les botnets se sont diffusées à l’ensemble de la cybercriminalité, puis ont essaimé dans certains segments de la criminalité dite « classique ». Pour aller plus loin, on peut lire notamment le livre de Benoît Dupont (La cybercriminalité, approche écosystémique de l’espace numérique, 2024), qui développe la notion de délinquance par projet.
Des cybermenaces aux écosystèmes criminels
À partir des années 2010, la cybercriminalité s’est profondément reconfigurée. Les opérations se sont fragmentées en une multitude de rôles spécialisés : développeurs de malwares, opérateurs d’accès initiaux, gestionnaires d’infrastructures, revendeurs de données, blanchisseurs, fournisseurs de services techniques et comme le décrit Benoît Dupont (ibid.), elle est articulée par un marché de services qui permet de recruter, louer ou remplacer chaque compétence selon les besoins du moment. Cette segmentation, combinée à une forte externalisation, a permis l’émergence de véritables chaînes de valeur (van Wanberg et al., 2017) criminelles, où chaque fonction peut être louée, remplacée ou automatisée.
Cette logique de modularité s’est installée comme norme. Les groupes (Nurse & Bada, 2019) n’exécutent plus l’ensemble de la chaîne : ils sélectionnent, achètent ou combinent des services — hébergement « bulletproof », crypteurs, kits prêts à l’emploi, proxys, accès initiaux, blanchiment. La résilience de ces structures repose précisément sur cette capacité à recomposer rapidement leurs liens lorsqu’un élément est perturbé.
Escroqueries en ligne : l’organisation derrière la masse
Les escroqueries en ligne illustrent parfaitement cette évolution. Elles ne sont plus le fait d’individus isolés, mais d’organisations qui combinent ingénierie sociale, infrastructures numériques, automatisation et logistique financière. Les analyses menées par Europol, l’UNODC et d’autres organismes montrent que ces réseaux fonctionnent comme de véritables entreprises criminelles : recrutement via réseaux sociaux, segmentation des tâches, scripts comportementaux, exploitation de messageries chiffrées, circulation de guides et tutoriels, plateformes internes, et conversion rapide des gains.
Au-delà de la variété des stratagèmes, c’est la structure qui importe : la fraude s’inscrit dans un environnement organisé, modulable et distribué — un écosystème. Et au cœur de cet écosystème, une technique revient systématiquement qui a son propre sous-écosystème, le hameçonnage.
Le hameçonnage : une activité devenue industrielle
Souvent présenté comme une simple manœuvre d’ingénierie sociale, le hameçonnage constitue aujourd’hui l’un des sous-systèmes les plus structurés de la criminalité numérique. Les recherches montrent (Alkhalil et al., 2021) que l’activité repose sur une répartition claire des rôles : conception de kits, développement d’infrastructures d’hébergement furtives, gestion des bases de cibles, automatisation de l’envoi, collecte d’identifiants, revente ou réutilisation des données.
Cette segmentation est soutenue par un marché florissant de phishing-as-a-service (PhaaS). Sur les places de marché criminelles circulent des kits intégrant pages clonées, modules anti-détection, systèmes de cloaking, anti-bot, tableaux de bord de suivi en temps réel, mises à jour automatiques et intégrations vers Telegram ou d’autres messageries.
Et dans le même temps, les botnets tiennent depuis longtemps une place centrale dans cet ensemble (OCDE, 2010) :
- comme plateformes d’envoi (Zhuang et al, 2008), permettant de diffuser à grande échelle des campagnes de hameçonnage en contournant les dispositifs anti-spam ;
- comme infrastructures de soutien, hébergeant ou relayant des pages de phishing via des réseaux distribués tels que le fast-flux.
Les opérations judiciaires récentes ont mis en lumière la solidité de ces écosystèmes. Le démantèlement de QakBot, en 2023, a révélé une infrastructure utilisée pour des campagnes de hameçonnage sophistiquées reposant sur le détournement de conversations existantes et la livraison de payloads à d’autres groupes. Emotet, avant lui, avait illustré (CERT-FR, 2021) la capacité d’un réseau à combiner propagation par hameçonnage, services de location d’accès et diffusion de charges malveillantes.
Dans ces exemples, le hameçonnage n’est pas une opération isolée : il est la porte d’entrée d’un système — un maillon essentiel d’un écosystème qui articule outils, infrastructures, compétences et marchés.
Une dynamique qui dépasse le numérique
Cette logique écosystémique dépasse aujourd’hui le périmètre de la cybercriminalité. Le trafic de stupéfiants, notamment, s’est structuré autour de pratiques similaires (UNODC, 2024) : recrutement, segmentation, logistique numérique, utilisation des réseaux sociaux, cryptomonnaies, sous-traitance de tâches techniques ou opérationnelles. Il n’est pas question de dire que ces phénomènes sont identiques, mais d’observer qu’ils partagent des mécanismes organisationnels comparables.
Ainsi, dans un autre rapport de l’UNODC centré sur l’Asie du Sud-Est, l’agence confirme que les criminels ont adopté des technologies avancées — malware, cryptomonnaies, IA générative — pour renforcer leurs capacités, automatiser des tâches, diversifier leurs méthodes et faciliter le blanchiment de sommes massives. Ces innovations leur permettent de déplacer leurs activités entre juridictions, d’adapter continuellement leurs modèles économiques et de contourner plus efficacement les mesures de répression. Ces groupes s’appuient fortement sur des places de marché clandestines, notamment sur Telegram, où s’échangent services, données volées, outils de fraude, solutions de blanchiment et travail forcé. Ces plateformes jouent un rôle central dans l’entretien et l’expansion d’un écosystème criminel transnational particulièrement résilient. Aussi, la taille colossale de cette économie criminelle a entraîné une industrialisation des opérations de fraude. De petits groupes dispersés ont été remplacés par des organisations plus grandes, plus structurées et souvent installées dans des parcs industriels, zones économiques spéciales, casinos ou hôtels, qui servent de bases d’opérations criminelles. Ces sites accueillent plusieurs acteurs différents, chacun menant des activités illicites variées à destination de victimes dans le monde entier.
Des organisations plus nébuleuses : l’exemple de ShinyHunters
Parmi les évolutions récentes, le cas de ShinyHunters, actif depuis 2019, illustre bien la manière dont certains groupes de cybercriminalité s’organisent autour de chaînes de valeur distribuées. Le groupe devient visible par une série de vols massifs de données — notamment Tokopedia, Unacademy, Wattpad ou Nitro PDF — puis par la revente ou l’extorsion de ces bases sur des forums de marché tels que BreachForums.
En 2024, ShinyHunters apparaît au centre de l’affaire Snowflake, dans laquelle les données de plusieurs entreprises — dont Ticketmaster et Santander — ont été exfiltrées à partir de comptes Snowflake compromis. Les analyses publiques indiquent que les attaquants ont utilisé des identifiants volés issus d’infostealers, l’absence de MFA sur certains comptes, puis ont proposé à la vente des téraoctets de données clients.
Depuis 2025, plusieurs travaux de threat-intelligence attribuent également au groupe le vol de données provenant de centaines d’instances Salesforce, via la compromission de jetons OAuth liés à l’outil Drift/Drift Email récupérés dans un dépôt GitHub de Salesloft. Les attaquants revendiquent environ 1,5 milliard d’enregistrements et engagent une campagne d’extorsion. Salesforce a publiquement confirmé l’incident côté fournisseurs tiers, tout en refusant de négocier avec les auteurs.
Les enquêtes judiciaires confirment par ailleurs l’existence d’un écosystème distribué : l’arrestation et la condamnation d’un suspect présenté comme membre du groupe en 2024 n’ont pas mis fin à ses activités, et les arrestations réalisées en France en 2025 autour de l’administration de BreachForums suggèrent l’existence de plusieurs cercles opérant sous la même bannière.
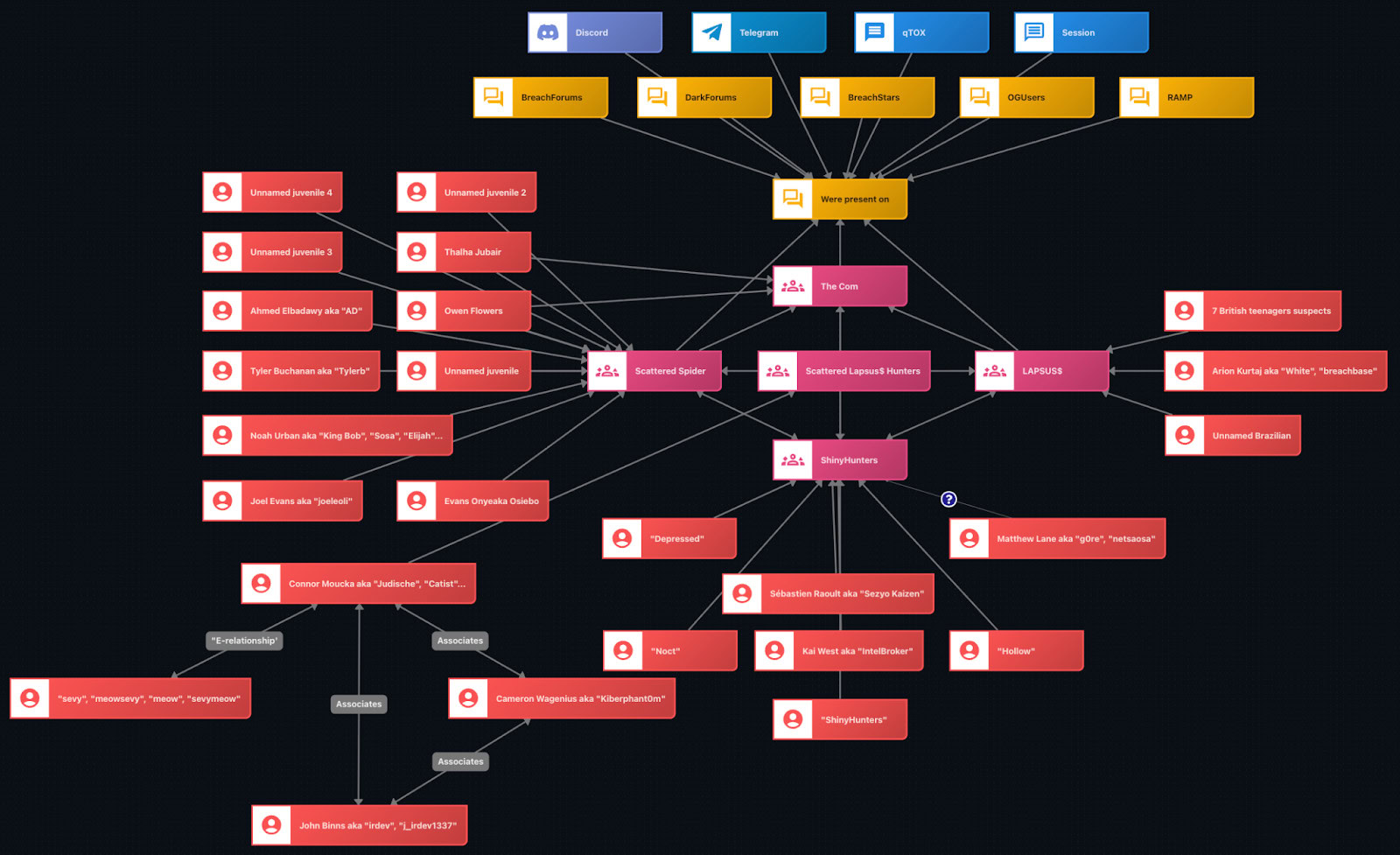
Pour ajouter à la complexité dans l’observation de ces groupes, si ShinyHunters semble bien distinct des groupes comme Lapsus$ ou Scattered Spider, plusieurs analyses soulignent l’existence d’une alliance opportuniste apparue en 2024-2025 sous le nom de Scattered Lapsus$ Hunters (SLH) : un « super-groupe » ou une « marque fédérée » utilisée par différents acteurs, notamment sur Telegram.
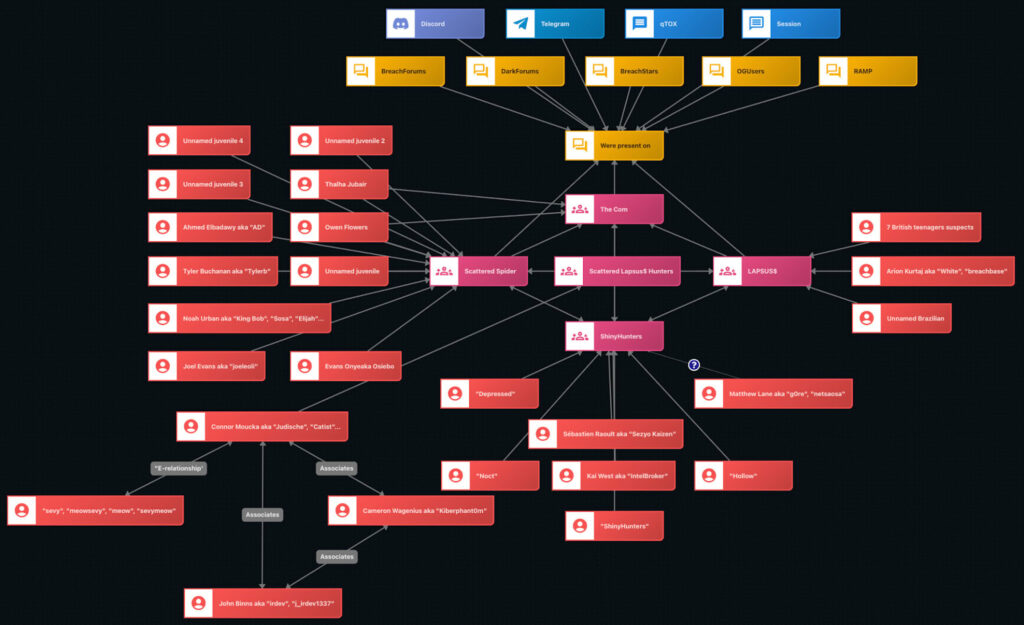
Des membres connus de ShinyHunters, Lapsus$, Scattered Spider et The Com ont été arrêtés. À noter que les affiliations multiples ne sont pas indiquées pour préserver la lisibilité (Source : Flare)
Ce type d’organisation — identités mouvantes, absence de hiérarchie stable, capacité à se recomposer malgré les arrestations — confirme la nécessité de considérer ces menaces comme des écosystèmes, où se combinent rôles spécialisés, infrastructures distribuées, accès compromis et marchés de données.
Penser et agir “en écosystème”
Pour les acteurs judiciaires comme pour les chercheurs, cette transformation impose de poursuivre notre adaptation dans la manière d’analyser et de traiter la criminalité :
- Élaborer une lecture systémique des menaces.
Une campagne de hameçonnage ou un botnet n’est jamais un phénomène isolé. C’est l’expression d’un système distribué, où chaque action est soutenue par d’autres acteurs, services et infrastructures.
- Viser les dépendances plutôt que les seuls opérateurs.
L’efficacité de la réponse tient dans l’identification des intermédiaires, des services loués, des flux techniques et économiques qui rendent l’organisation possible.
- Perturber les chaînes, pas seulement les symptômes.
Neutraliser un serveur ou arrêter un individu est souvent insuffisant si l’écosystème peut se recomposer immédiatement. Une action efficace doit cibler les points d’ancrage : hébergement, proxys, prestataires spécialisés, flux financiers, mécanismes de recrutement. C’est ce que permet notamment la répétition des opérations internationales coordonnées comme Endgame.
- Mobiliser l’interdisciplinarité.
L’analyse technique doit être combinée à des approches issues de la criminologie, de la psychologie, de l’économie criminelle et de l’analyse de données. C’est l’une des ambitions poursuivies dans le cadre du programme Defmal du PEPR Cybersécurité (atelier du 12 mars 2025).
- Construire une capacité d’anticipation.
La proactivité n’est plus un luxe : c’est une condition de l’efficacité. Comprendre les écosystèmes criminels, c’est comprendre où ils peuvent être fragilisés — et agir avant qu’ils ne se reconfigurent. C’est aussi les détecter le plus tôt possible, quand ils se constituent leurs infrastructures et que se met en place leur coordination.
Dix ans après avoir terminé mes travaux de thèse, les botnets apparaissent ainsi non comme un objet du passé, mais comme un modèle analytique qui éclaire toute une série de phénomènes criminels contemporains. Ce ne sont plus seulement des machines compromises : ce sont des structures, des acteurs, des relations. Des écosystèmes. Et c’est résolument à cette échelle qu’il faut penser et agir.